

文本处理
一、字段截取
1.1 cut字段提取命令
- 格式:cut -d【间隔符】 -f【列号】 -c【字符】
- cut [选项] 文件名
- 区别:grep是行提取命令,cut是列提取命令
-d : 指定分隔符类型
-f : 指定打印第几列
-c : 按字符分割,按照单个字符进行分割
比如:asdfghj
cut -c 2-4
截取到的就是 sdf
[root@myx ~]# cat test
name age addr Tel
zhangsan 20 shanghai 100
lisi 30 hangzhou 120
wangwu 40 wuhan 130
zhaosi 25 xianning 200
# 指定分隔符提取 -d【间隔符】 -f【行号】
[root@myx ~]# cut -d' ' -f4 test
Tel
100
120
130
200
# 指定字符数来提取
[root@myx ~]# cut -c 1-4 test
name
zhan ##显示1-4列所有字段
lisi
wang
zhao
# cut配合grep使用
[root@myx ~]# cp /etc/passwd .
1)例如我们需要过滤passwd文件中第一列的root这个用户
[root@myx ~]# cat passwd |grep /bin/bash|cut -f 1 -d ":"|grep root
root
2) 例如我们需要过滤passwd文件中第一列为非root的用户
[root@myx ~]# [root@myx ~]# cat passwd |grep /bin/bash|cut -f 1 -d ":"|grep -v root
...
user1
user2
3)例如截取根分区下的磁盘空间使用率
[root@myx ~]# df -h
文件系统 容量 已用 可用 已用% 挂载点
devtmpfs 1.9G 0 1.9G 0% /dev
tmpfs 1.9G 0 1.9G 0% /dev/shm
tmpfs 1.9G 12M 1.9G 1% /run
tmpfs 1.9G 0 1.9G 0% /sys/fs/cgroup
/dev/mapper/centos-root 37G 5.2G 32G 14% /
/dev/sr0 4.4G 4.4G 0 100% /localrepo
/dev/sda1 1014M 151M 864M 15% /boot
tmpfs 378M 0 378M 0% /run/user/0
[root@myx ~]# df -h |grep /dev/sda1 | tr -s ' ' '%' | cut -f 4 -d '%'
864M
4)获取网卡的IP
# 按照字符截取
[root@myx ~]# ifconfig eth0 |head -2|tail -1 |cut -c 13-21
10.0.0.8
# grep过滤截取
[root@myx ~]# ifconfig eth0 |grep broadcast |tr -s ' ' '%'|cut -d% -f3
10.0.0.8
# head
-n <行数>:指定要显示的行数,默认为10行。
-c <字节数>:按字节数而不是行数来显示文件的开头内容。
[root@myx ~]# ifconfig eth0 |head -2|tail -1 |tr -s ' ' '%' |cut -d% -f3
10.0.0.8
5)统计http所有的访问日志中的来源IP地址
[root@myx ~]# cut -d' ' -f1 /var/log/httpd/access_log
192.168.110.11
1.2 printf命令
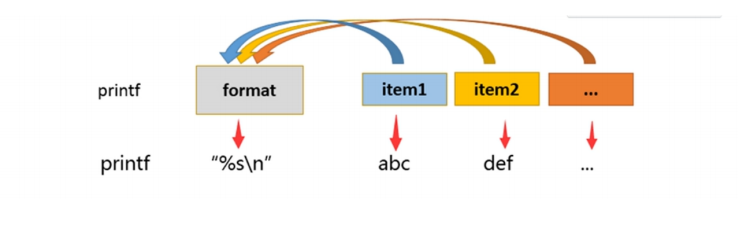
- 格式 : printf '输出类型和输出格式' 输出内容
输出类型
1). %ns: 输出字符串。n是数字,指代输出几个字符
2). %ni: 输出整数。n是数字,指代输出几个数字
3). %m.nf: 输出浮点型。m和n是数字,指代输出的整数位数和小数位数。如%8.2f,代表共输出8位数,其
中2位是小数,6位是整数。
输出格式类型
- 常用:\n 、\t、\v
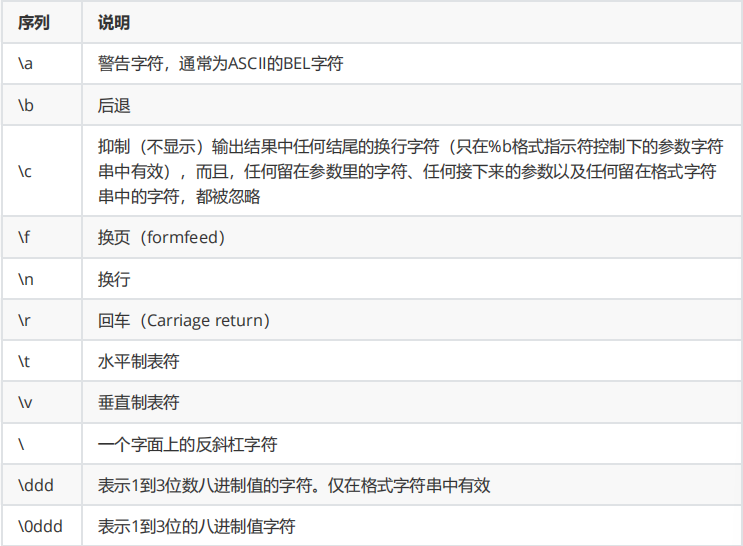
printf格式指示符
- 常用:%e %E %d,%i
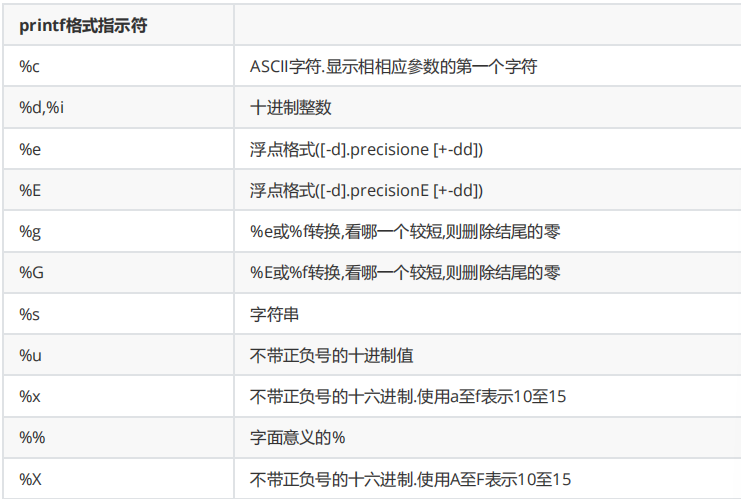
精度的含义
1.3 cat命令
- 语法 : cat [选项] [文件名]
常见选项:
-A: 输出所有的隐藏字符
-b:给非空输出行编号,使 -n 失效。
-E:在每行结束显示 $
-n:给所有输出行编号
-s:将所有的连续的多个空行替换为一个空行
涉及:
tac:逆向显示行内容
rev:逆向显示文本内容
nl:显示行号
cat合并文件
cat -n 文件1 >> 文件2
将文件1显示行号后追加到文件2中
cat创建文件
1)cat > 文件名
2)cat > 文件名 << EOF
EOF
##重定向输入
[root@myx ~]# cat >file1</etc/passwd
1.4 合并文件
- 语法:paste [参数] [文件1] [文件2] 常用参数:

- 设置域分隔符为:粘贴成新的文件:
[root@myx ~]# paste -d : file1 file2
1111:1111
2222:2222
3333:3333
4444:4444
5555:5555
6666:6666
7777:7777
:8888
- 将每个文件粘贴成一行:
[root@myx ~]# paste -d : -s file1 file2
1111:2222:3333:4444:5555:6666:7777
1111:2222:3333:4444:5555:6666:7777:8888
- 从标准输入中读取数据,每行显示3个内容:
[root@myx ~]# cat file1|paste -d " " - - -
1111 2222 3333
4444 5555 6666
7777
[root@myx ~]# cat file1|paste - - -
1111 2222 3333
4444 5555 6666
7777
1.5 vimdiff
- vimdiff 等同于 vim -d 命令
- 语法:vimdiff FILE_LEFT FILE_RIGHT 常用命令
:qa:退出所有文件
:wa:保存所有文件
:wqa:保存并退出所有文件
qa!:强制退出(不保存)所有文件
示例:
# 对比2个文件的差别
[root@myx ~]# vim -O file1 file2
O横向对比
文件差异
o纵向对比
[root@myx ~]# vimdiff file1 file2
高亮显示文件差异
- 光标移动:
可以使用下列两种快捷键,在文件的各个差异点之间前后移动:
], c :跳转到下个差异点
[, c :跳转到上个差异点
Ctrl-w, w :光标在两个窗口间彼此切换
- 内容合并
可以使用 d, p (即 diff put)命令,将当前差异点中的内容覆盖到另一文件中的对应位置。
如当光标位于左侧文件(file1)中的第6行时,依次按下 d 、 p 键,则 file1 中的 第六行 被推送到
右侧,并替换掉 file2 中对应位置上的 第六行 。
1.6 diff
- 语法:diff 【选项】 源文件(夹) 目的文件(夹) 常见选项
-r 是一个递归选项,设置了这个选项,diff会将两个不同版本源代码目录中的所有对应文件全部都进行一次
比较,包括子目录文件。
-b 忽略空格数目的不同
-u 选项以统一格式创建补丁文件,这种格式比缺省格式更紧凑些。
-W 在使用-y参数时,指定栏宽
-y 以并列的方式显示文件的异同之处。
-e 此参数的输出格式可用于ed的script文件。
示例
使用-e和ed同步f2内容到f1
[root@myx ~]# yum -y install ed
[root@myx ~]# diff -e f1 f2 >f.patch
[root@myx ~]# echo "w" >> f.patch #w代表write写指令
[root@myx ~]# ed - f1 <f.patch
- 目录比较:
[root@myx ~]# diff d1 d2
Only in d1: f1
Only in d2: f2
- 生成差异文件
[root@myx ~]# diff -u f1 f2 >f.patch
1.7 patch
- 语法:patch [option] [origfile] [patchfile]
常用选项参数:
-r 是一个递归比较,包括子目录文件。
-N 选项确保补丁文件将正确地处理已经创建或删除文件的情况。
-u 选项以统一格式创建补丁文件,这种格式比缺省格式更紧凑些。
-b 备份每一个原始文件
-p0 指定补丁文件的层级为 0,表示直接应用补丁文件,不进行任何层级检查。
-p1 指定补丁文件的层级为 1,表示将补丁文件应用于第一层目录中的文件。如果补丁文件不存在于第一层目
录中,则应用失败。
-E 发现空文件删除
-R 给新版本打补丁,让它变成老版本
- 示例:将补丁打入f1文件
[root@myx ~]# diff -u f1 f2 >f.patch
[root@myx ~]# patch -p0 f1<f.patch
[root@myx ~]# cat f1
#反向补丁,用于回退补丁
[root@myx ~]# patch -Rp0 f1 <f.patch
- 示例:恢复原文件
[root@myx ~]# rm -rf f2 ##模拟删除f2文件
[root@myx ~]# patch -b f1 f.patch ##使用f.patch文件来恢复f2,-b表示备份
patching file f1
[root@myx ~]# cat f1 ##f2文件被命名成了f1
[root@myx ~]# cat f1.orig ##原来的f1文件被命名成了f1.orig
二、grep命令
- 语法:grep [OPTIONS] PATTERN [FILE…] 常见选项
--color=auto 对匹配到的文本着色显示
-m # 匹配#次后停止
-v 显示不被pattern匹配到的行,取反
-i 忽略字符大小写
-n 显示匹配的行号
-o 仅显示匹配到的字符串(感兴趣的内容)
-q 静默模式,不输出任何内容
-A # after,后#行
-B # before,前#行
-C # context,前后各#行
-e 实现多个选项间的逻辑or关系,如:grep -e 'cat' -e 'dog' file
-w 匹配整个单词
-E 使用ERE,相当于Egrep,扩展正则表达式
-F 禁用正则表达式,相当于fgrep
-f file 根据模式文件处理
-r 递归目录,不处理软链接
-c 小写字母c表示统计过滤信息的次数
三、sort 排序或者去重
- 语法:sort [选项] filename 常用选项
-u :去重
-n :以数值来排序
-o :将结果写入原文件
-r :降序
-t :指定分割符
-k :指定列
-R: 随机排序
案例
# 去重
[root@myx ~]#cat a.txt
aaaaabc
aaaaaac
abbbbb
abbbbb
[root@myx ~]#sort -u a.txt
aaaaaac
aaaaabc
abbbbb
# 数值型排序
[root@myx ~]#cat b.txt
1
2
4
10
15
24
5
3
[root@myx ~]#sort -n b.txt
1
2
3
4
5
10
15
24
# 把排序结果输出到原文件中 -o
[root@myx ~]#cat b.txt
5
10
15
24
[root@myx ~]#sort -n b.txt -o c.txt
[root@myx ~]#cat c.txt
5
10
15
24
# sort标准输入和标准输出
[root@myx ~]#cat n1.txt
3
5
7
1
11
[root@myx ~]#sort -n <n1.txt >n2.txt ##由n1.txt读取数据,经过排序后输出至n2.txt
[root@myx ~]#cat n2.txt
1
3
5
7
11
# 降序
[root@myx ~]#cat c.txt
10
15
24
5
[root@myx ~]#sort -r c.txt
5
24
15
10
如何获取当前系统中磁盘的最大利用率?
[root@myx ~]#df -h |tr -s ' ' '%'|cut -d% -f5|sort -nr |head -1
100
四、 uniq 去重
- 语法:uniq [选项] [filename] 常用选项与参数
-i :忽略大小写字符的不同;
-c :进行计数
-u :只显示不重复的行
-d : 显示重复的行
案例
# 排序后去重
[root@myx ~]#sort -n d.txt | uniq
hello
shanghai
welcome
world
wuhan
# 去重并显示重复的行数
[root@myx ~]#sort -n d.txt | uniq -c
2 hello
1 shanghai
1 welcome
1 world
2 wuhan
# 仅显示重复的行
[root@myx ~]#sort -n d.txt | uniq -dc
2 hello
2 wuhan
# 过滤2个文件相同的行和不同的行
[root@myx ~]#cat test1
a
b
c
c1
c2
dd
ff
1
2
[root@myx ~]#cat test2
a
d
c1
c22
c6
aa
f
11
2
# 显示重复的行
[root@myx ~]#cat test1 test2 | sort | uniq -d
2
a
c1
# 显示不重复的行
[root@myx ~]#cat test1 test2 | sort | uniq -u
1
11
aa
b
c
c2
c22
c6
d
dd
f
ff
# 过滤当前主机上的访问日志的访问量
[root@myx ~]#cat /var/log/httpd/access_log |cut -d ' ' -f1|sort|uniq -c |sort
11 192.168.110.13
25 192.168.110.11
tail -n+2 表示是从第二行开始取值。
# 查看当前的服务器的连接数,并显示连接数最多的IP地址
[root@myx ~]#ss -nt | tail -n+2 | tr -s ' ' '%' | cut -d% -f5 | cut -d: -f1 | sort | uniq -c | sort -nr 1 10.0.0.66
五、tee 命令
- 示例
[root@myx ~]# echo "abc" |tee /data/test.log
-a选项可以表示追加
[root@myx ~]# echo "aaaa" |tee -a /data/test.log
tee命令和tr命令结合使用
[root@myx ~]# echo "aaaa" |tee -a /data/test.log |tr "a-z" "A-Z"
案例
[root@myx ~]#cat <<EOF | tee .mailrc
> 123
> abc
> 456
> def
> EOF
123
abc
456
def
# 把输入的内容输出一遍,并插入到 .fmailrc文件中
六、WC命令
- 语法:wc [-clw] filename 常用参数
-c或--bytes或--chars 只显示Bytes数。
-l或--lines 只显示列数。
-w或--words 只显示字数。
在默认的情况下,wc将计算指定文件的行数、字数,以及字节数。使用的命令为:
[root@myx ~]# wc test.txt
七、tr命令
-
替换操作的字符串转换。
-
删除操作的字符串转换,可以很容易的删除一些控制字符或者是空行。
命令格式
用法1:将命令的执行结果交给tr处理,其中string1是用于查询,string2用于转换处理
#command |tr [option] ["string1"] ["string2"]
用法2:tr处理的内容来自于文件,使用"<"
#tr [option] ["string1"] ["string2"] <file
用法3:匹配string1的内容,并进行操作,比如删除
#tr [option] ["string1"] <file
常用选项
1. 默认选项。就是没有任何选项的时候,tr默认为替换操作,就是将string1在文件中出现的字符替换为
string2中的字符,这里要注意的是替换关系。
2. -d选项,删除文件中所有在string1中出现的字符。
3. -s选项,删除文件中重复并且在string1中出现的字符,只保留一个。
4. -c选项 用SET2替换SET1中没有包含的字符
-
字符串的取值范围
指定string或string2的内容时,只能使用单字符或字符串范围或列表。
1. [a-z]或者[:lower:]a-z内的字符组成的字符串。
2. [A-Z] 或者[:upper:]A-Z内的字符组成的字符串。
3. [0-9]或者[:digit:] 数字串。
4. [:alnum:] 所有的字母和数字
5. [:alpha:] 字母
6. [:blank] 匹配所有的空白
7. [:space:] 所有的横向或纵向的空白
8. \octal 一个三位的八进制数,对应有效的ASCII字符。
9. [O*n] 表示字符O重复出现指定次数n。因此[O*2]匹配OO的字符串。
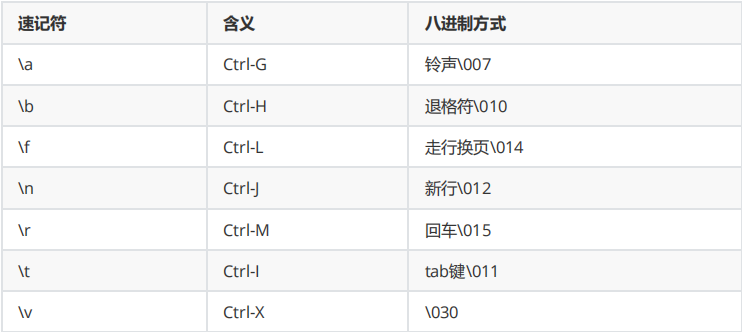
- 控制字符的不同表达方式

阅读建议

评论
匿名评论
隐私政策
你无需删除空行,直接评论以获取最佳展示效果